commit/bb3451f035c1e2f6aaa440a87a63893c1d955390
时间分析
这一届我们将提升我们的生命游戏实现的性能。我们将使用时间分析来知道我们的工作。
在继续之前请先熟悉用于Rust和WebAssembly代码的时间分析工具。
使用window.performance.now函数创建一个帧率计时器
随着我们加快我们的生命游戏渲染,这个FPS计时器将会非常有用。
我们先添加一个fps对象到wasm-game-of-life/www/index.js:
const fps = new class {
constructor() {
this.fps = document.getElementById("fps");
this.frames = [];
this.lastFrameTimeStamp = performance.now();
}
render() {
// 将自上一次渲染帧的时间增量转换为fps的测量。
const now = performance.now();
const delta = now - this.lastFrameTimeStamp;
this.lastFrameTimeStamp = now;
const fps = 1 / delta * 1000;
// 只保存最新的100个时间
this.frames.push(fps);
if (this.frames.length > 100) {
this.frames.shift();
}
// 找出100个最近时间的最大值,最小值和平均值。
let min = Infinity;
let max = -Infinity;
let sum = 0;
for (let i = 0; i < this.frames.length; i++) {
sum += this.frames[i];
min = Math.min(this.frames[i], min);
max = Math.max(this.frames[i], max);
}
let mean = sum / this.frames.length;
// 渲染统计信息。
this.fps.textContent = `
Frames per Second:
latest = ${Math.round(fps)}
avg of last 100 = ${Math.round(mean)}
min of last 100 = ${Math.round(min)}
max of last 100 = ${Math.round(max)}
`.trim();
}
};
接下来我们在每次renderLoop迭代时调用fps和render函数:
const renderLoop = () => {
fps.render(); //new
universe.tick();
drawGrid();
drawCells();
animationId = requestAnimationFrame(renderLoop);
};
最后,不要忘记把fps元素添加到wasm-game-of-life/www/index.html,就在<canvas>上面:
<div id="fps"></div>
然后添加CSS让格式好一些:
#fps {
white-space: pre;
font-family: monospace;
}
瞧!刷新http://localhost:8080我们就有了一个FPS计数器。
用console.time和console.timeEnd给每次Universe::tick计时
为了测量每次调用Universe::tick花费了多久,
我们可以通过web-sys使用console.time和console.timeEnd。
首先,将web-sys作为依赖添加到wasm-game-of-life/Cargo.toml:
[dependencies.web-sys]
version = "0.3"
features = [
"console",
]
因为每个console.timeEnd调用都应该有一个对应的console.time调用,
所以将他们封装为RAII类型很方便:
extern crate web_sys;
use web_sys::console;
pub struct Timer<'a> {
name: &'a str,
}
impl<'a> Timer<'a> {
pub fn new(name: &'a str) -> Timer<'a> {
console::time_with_label(name);
Timer { name }
}
}
impl<'a> Drop for Timer<'a> {
fn drop(&mut self) {
console::time_end_with_label(self.name);
}
}
然后,把这个片段添加到方法的顶部我们就可以而是每次Universe::tick花费了多少时间:
let _timer = Timer::new("Universe::tick");
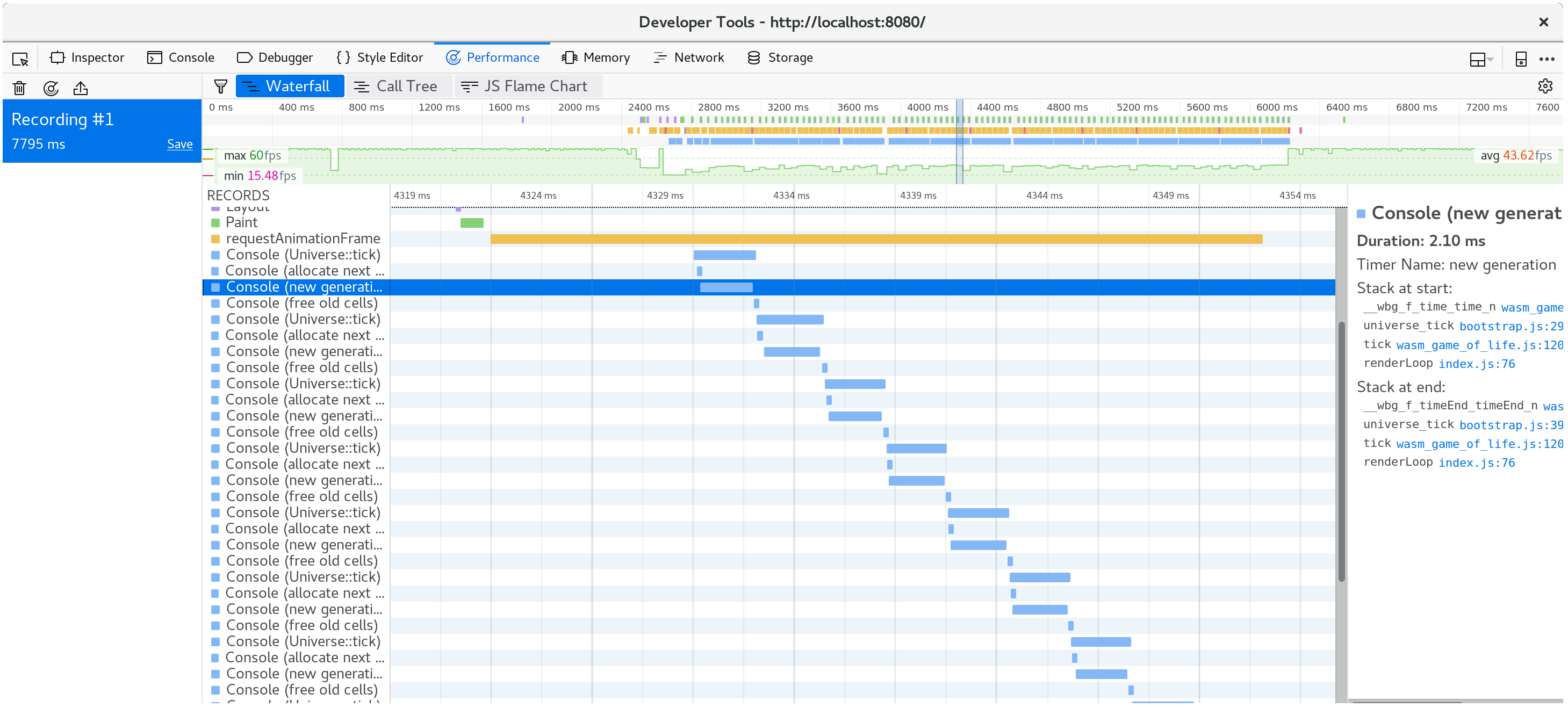
每次调用Universe::tick花费了多久时间现在被记录到了控制台:
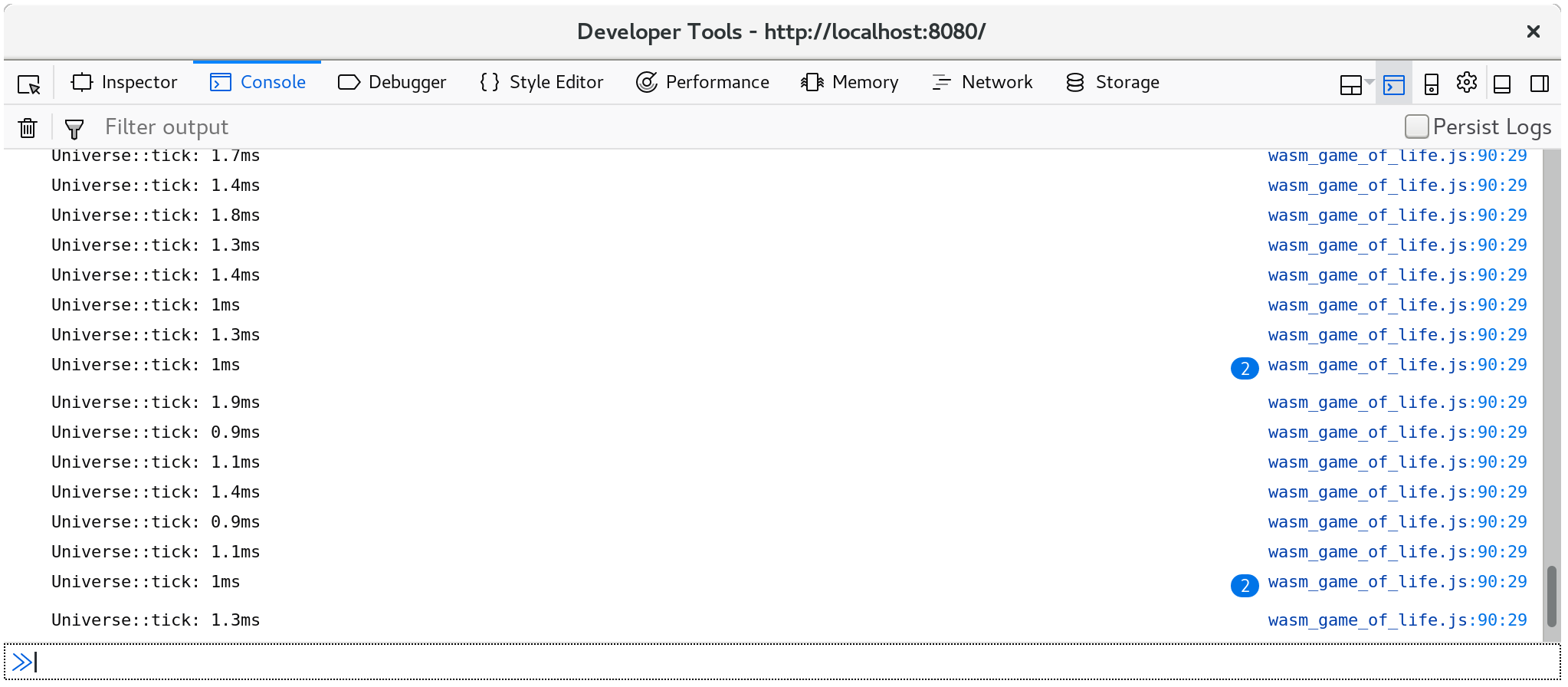
此外,console.time和console.timeEnd对将显示在浏览器的分析器的“时间轴”或“瀑布”视图中:pp
pp
发展我们的生命游戏宇宙
⚠️ 本节使用火狐的屏幕截图例子。 不过所有的现代浏览器都有相似的工具,虽然不同的开发者工具之间可能有细微的不同。 你摘录的面板信息本质上会是一样的,但是就不同工具的名字和你查看的视图而言,可能会有变化。
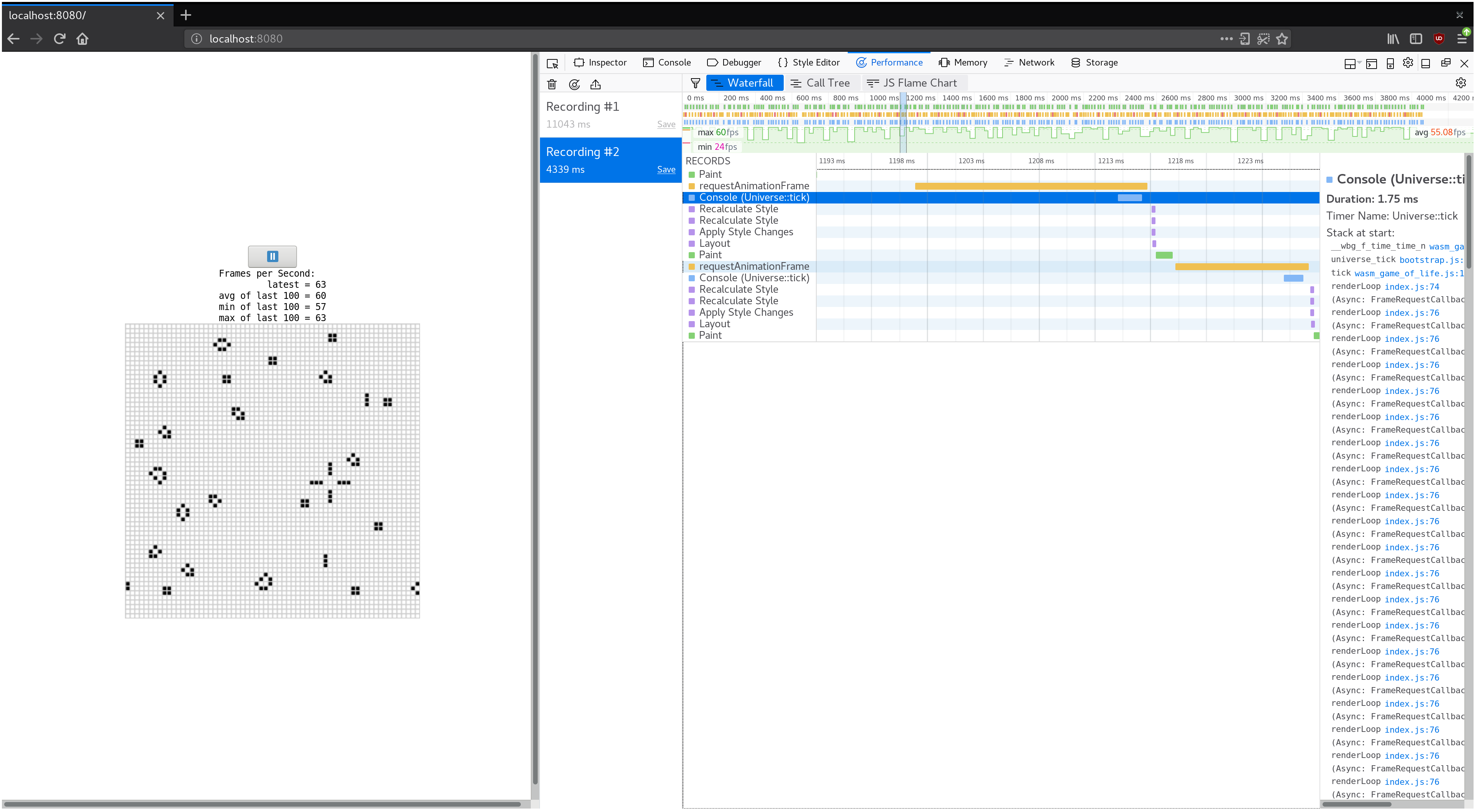
如果我们使我们的生命游戏的宇宙变得更大会发生什么?在我的机器上用128*128的宇宙取代64*64的宇宙
(修改wasm-game-of-life/src/lib.rs中的Universe::new)导致FPS从平滑的60下降到断续的40左右。
如果我们记录一个配置并看一下瀑布图,我们会发现每个动画帧花费了大概20毫秒。 回想一下,每秒60真那么渲染一帧的整个过程只剩下16毫秒。 这不仅仅是我们的JavaScript和WebAssembly,还有浏览器里正在进行的所有其他的事情的时间。例如绘制。
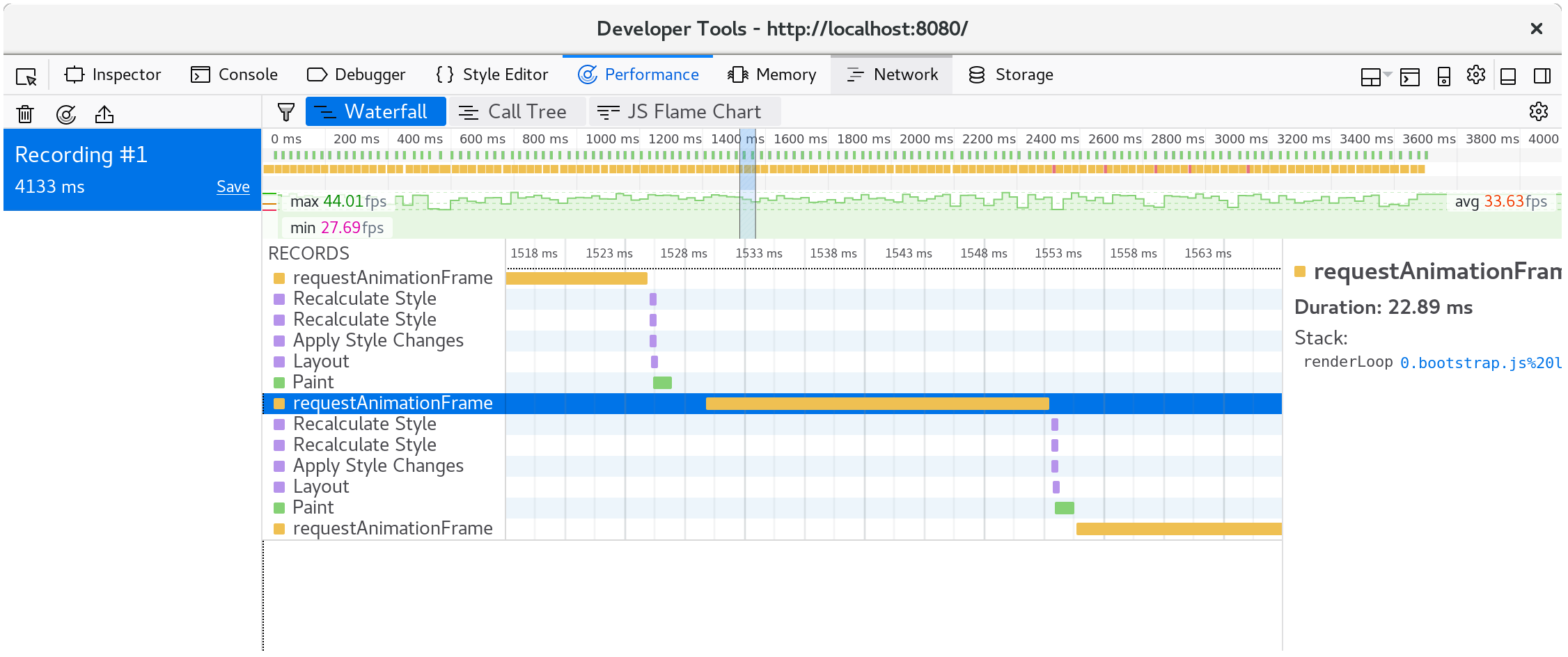
如果我们查看在一个单独的动画帧里发生了什么,我们发现CanvasRenderingContext2D.fillStyle是非常昂贵的!
⚠️ 在火狐中,如果你看见一行简单的描述为“DOM”而不是我们前面提到的
CanvasRenderingContext2D.fillStyle, 你可能需要在你的性能开发人员工具选项中打开“显示Gecko平台数据”选项:
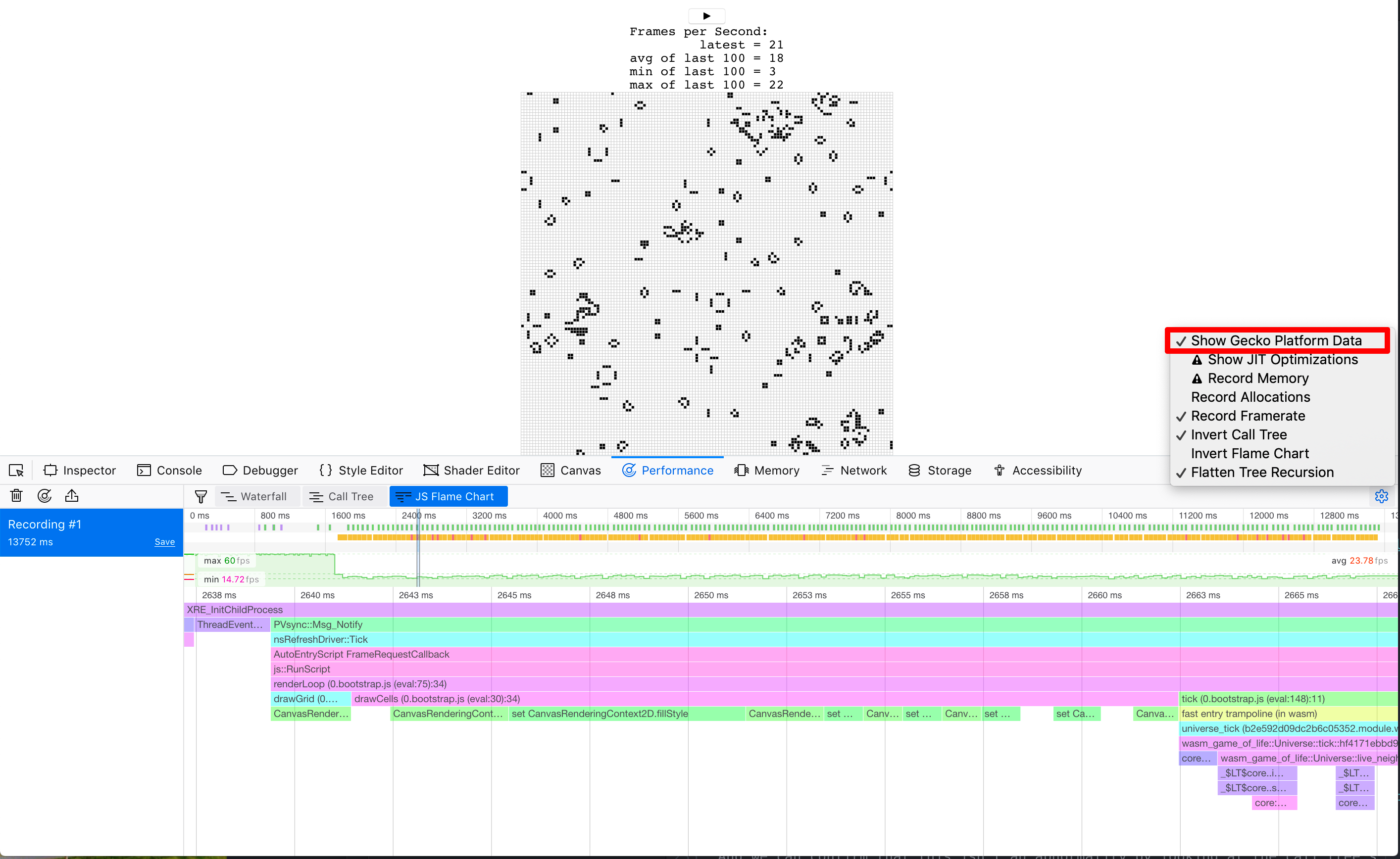
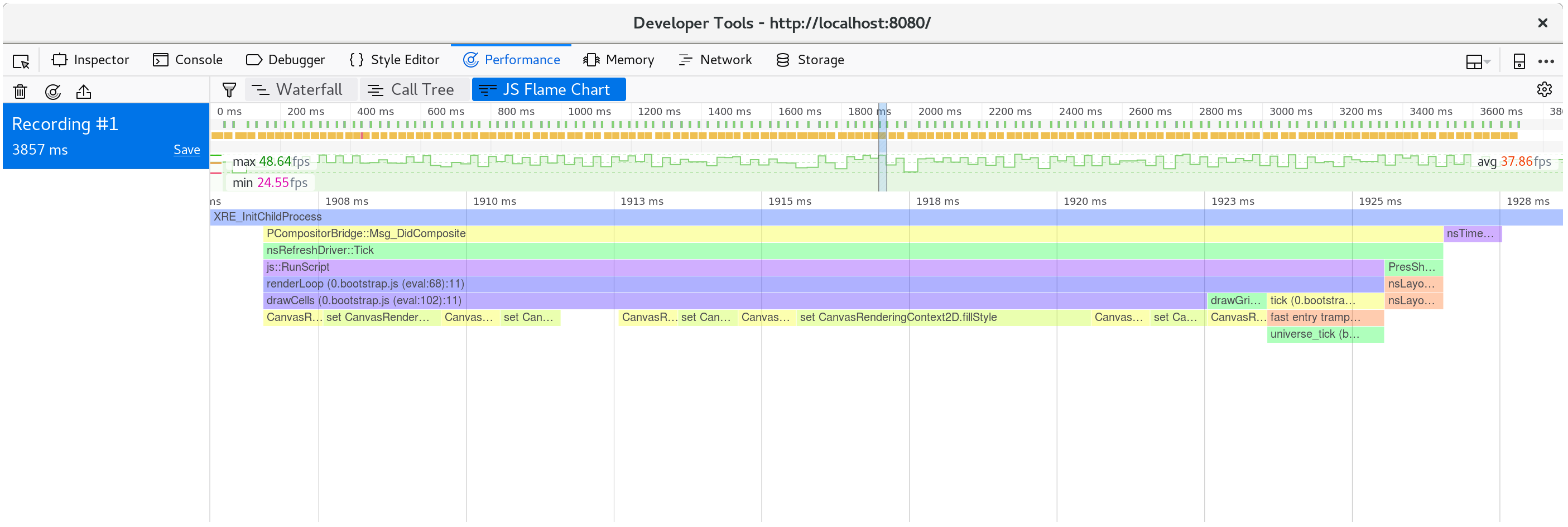
我们可以通过查看调用树的多个帧的聚合来确认这不是异常:
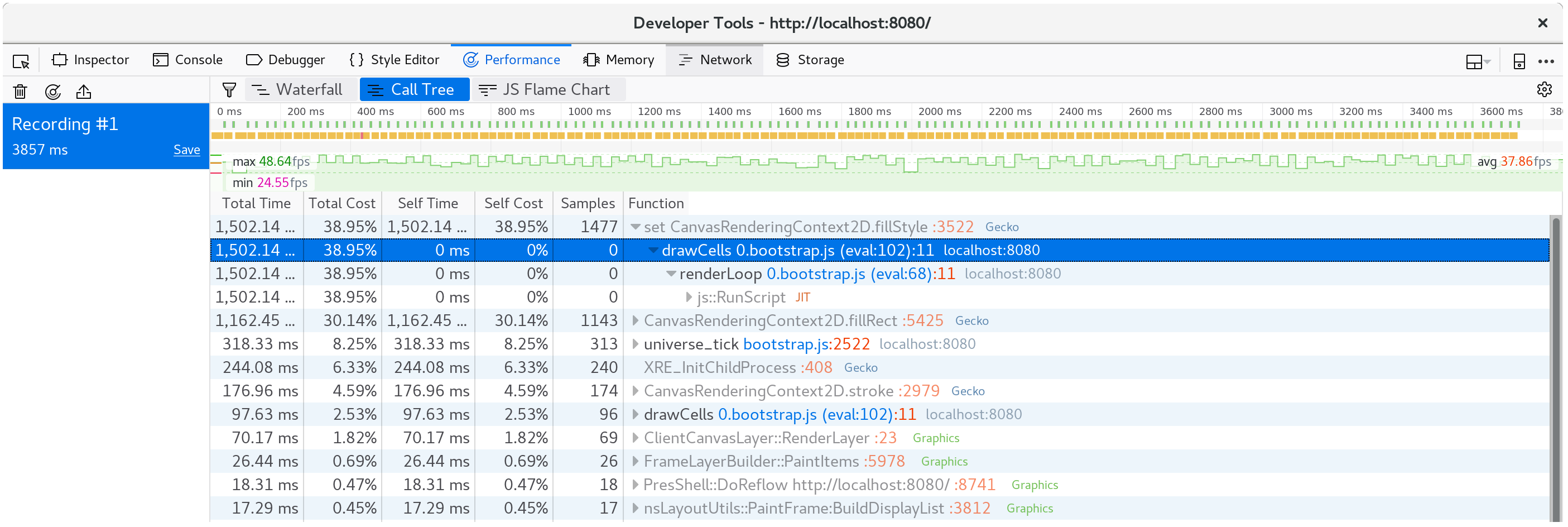
我们时间的40%几乎被花在了这个二传手上!
⚡ 我们可能期望
tick方法中的某些东西成为性能瓶颈,但事实并非如此。 永远要让分析带领你的关注点,因为时间可能消耗在你意料之外的地方。
在wasm-game-of-life/www/index.js中的drawCells函数内,
fillStyle属性为宇宙中的每个细胞在每个动画帧中都设置一次:
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
ctx.fillStyle = cells[idx] === DEAD
? DEAD_COLOR
: ALIVE_COLOR;
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
现在我们已经发现了设置fillStyle是昂贵的,我们可以做什么来避免频繁的设置它?
我们需要基于细胞是存活还是死亡来改变fillStyle。
如果我们设置 fillStyle = ALIVE_COLOR然后在一趟中绘制所有的存活细胞,
接着设置fillStyle = DEAD_COLOR再在另一趟中绘制所有的死亡细胞,
那么我们结束时只设置了两次fillStyle,而不是每个细胞一次。
// 活细胞。
ctx.fillStyle = ALIVE_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Alive) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
// 死细胞。
ctx.fillStyle = DEAD_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Dead) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
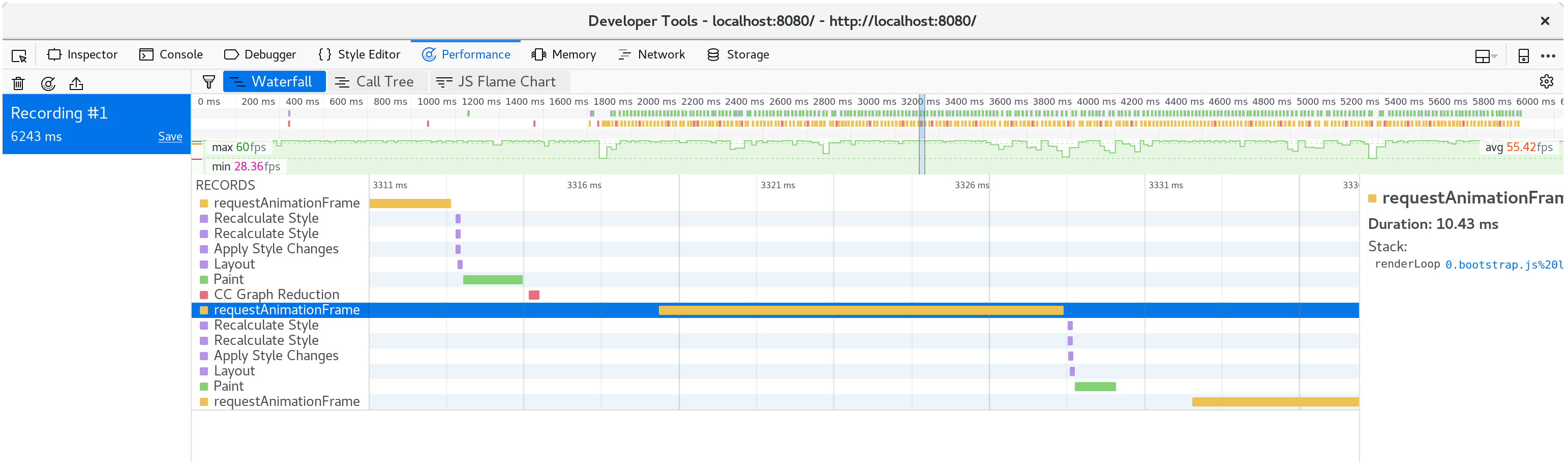
保存这些改变后刷新http://localhost:8080/, 渲染回到了平滑的60fps了。
如果我们再看一次面板,现在每个动画帧只花费大约10毫秒了。
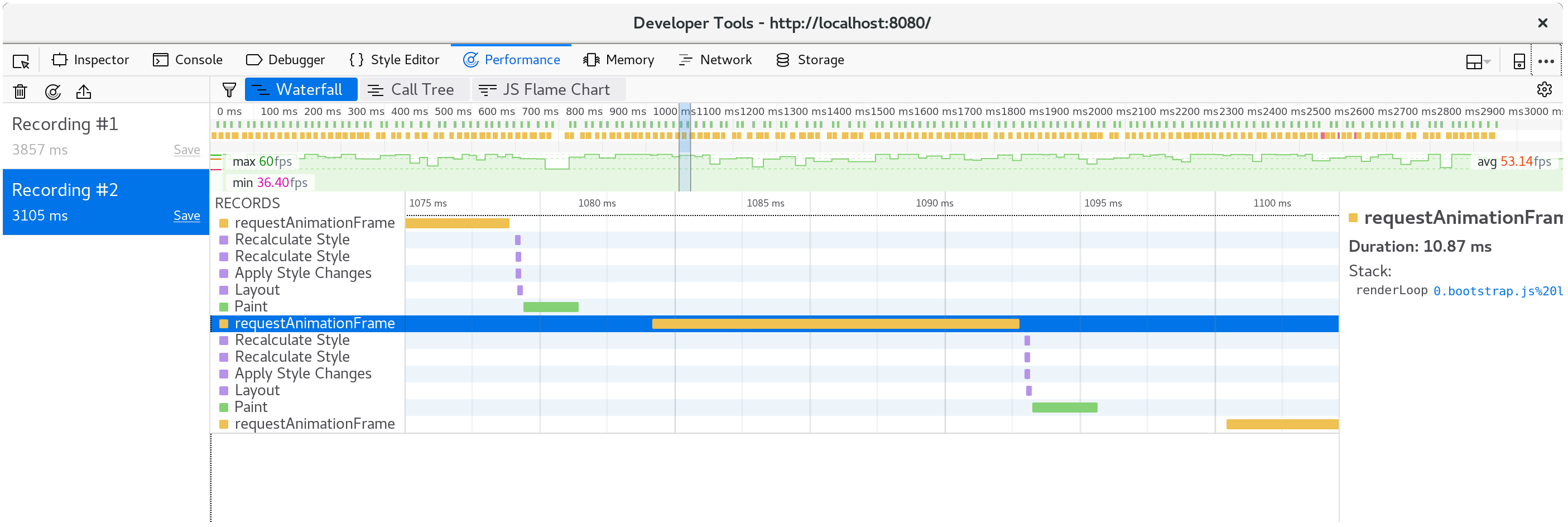
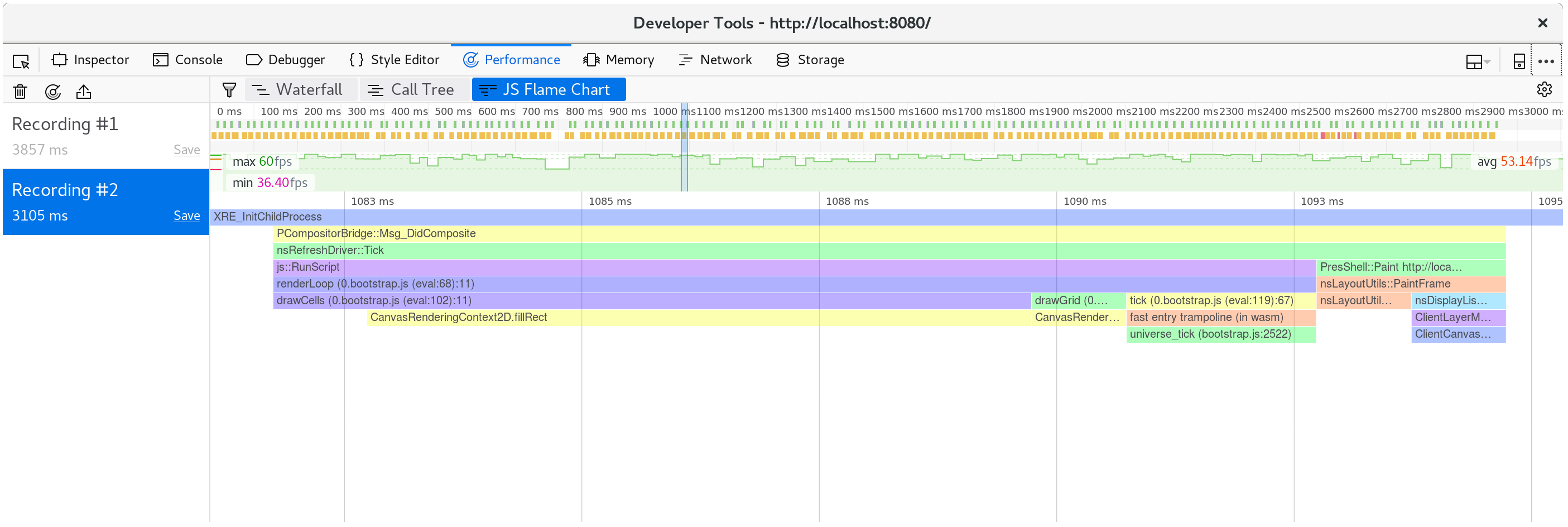
分解单个帧,我们看到fillStyle消耗已经消失了,
我们的帧的大部分时间都花费在fillRect,绘制每个细胞的矩形。
运行的再快点
有些人不喜欢等待,并且将想要每个动画帧里发生9次tick而不是1次。
我们可以修改wasm-game-of-life/www/index.js中的renderLoop函数,这做起来很容易:
for (let i = 0; i < 9; i++) {
universe.tick();
}
再我的机器上,这再次下降到每秒35帧。不好,我们想要到60!
现在我们知道了时间消耗再Universe::tick,
所以让我们添加一些Timer来包装console.time和console.timeEnd调用中的各个部分,
看看这会把我们引向何处。
我的假设是每个tick都分配细胞的新向量并释放旧向量是费时的,并且占据了我们时间预算的很大部分。
pub fn tick(&mut self) {
let _timer = Timer::new("Universe::tick");
let mut next = {
let _timer = Timer::new("allocate next cells");
self.cells.clone()
};
{
let _timer = Timer::new("new generation");
for row in 0..self.height {
for col in 0..self.width {
let idx = self.get_index(row, col);
let cell = self.cells[idx];
let live_neighbors = self.live_neighbor_count(row, col);
let next_cell = match (cell, live_neighbors) {
// Rule 1: Any live cell with fewer than two live neighbours
// dies, as if caused by underpopulation.
(Cell::Alive, x) if x < 2 => Cell::Dead,
// Rule 2: Any live cell with two or three live neighbours
// lives on to the next generation.
(Cell::Alive, 2) | (Cell::Alive, 3) => Cell::Alive,
// Rule 3: Any live cell with more than three live
// neighbours dies, as if by overpopulation.
(Cell::Alive, x) if x > 3 => Cell::Dead,
// Rule 4: Any dead cell with exactly three live neighbours
// becomes a live cell, as if by reproduction.
(Cell::Dead, 3) => Cell::Alive,
// All other cells remain in the same state.
(otherwise, _) => otherwise,
};
next[idx] = next_cell;
}
}
}
let _timer = Timer::new("free old cells");
self.cells = next;
}
看看计时,很明显我的假设是不正确的:大多数的时间实际上被花费在了计算下一代细胞。 每个tick分配和释放向量意外的占据了微不足道的花费。 再次提醒永远用分析知道我们的工作。
下一个部分要求使用nightly编译器。这是必须的,因为我们将要使用[test feature gate]
(https://doc.rust-lang.org/unstable-book/library-features/test.html)
进行基准测试。我们要安装的另一个工具是cargo benchcmp。
这是一个用于比较由cargo bench生成的微基准测试的小功能。
让我们写一份本地代码#[bench],它做了和我们的WebAssembly一样的事情,
不过这里我们可以使用更多成熟的分析工具。这是新的wasm-game-of-life/benches/bench.rs:
#![feature(test)]
extern crate test;
extern crate wasm_game_of_life;
#[bench]
fn universe_ticks(b: &mut test::Bencher) {
let mut universe = wasm_game_of_life::Universe::new();
b.iter(|| {
universe.tick();
});
}
我们还必须注释掉所有的#[wasm_bindgen]注解,
以及Cargo.toml中的"cdylib"以及其他会导致构建本地代码失败和链接错误的内容。
有了这些,我们可以运行cargo bench | tee before.txt来编译和运行我们的基准测试!
| tee before.txt将获取cargo bench的输出并将他放入一个叫before.txt的文件。
$ cargo bench | tee before.txt
Finished release [optimized + debuginfo] target(s) in 0.0 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 664,421 ns/iter (+/- 51,926)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
这也告诉了我们二进制文件存放的位置,我们可以再次运行基准测试,
不过这一次是在我们的操作系统的分析器下。
我运行在Linux上,所以我使用的分析器时perf:
$ perf record -g target/release/deps/bench-8474091a05cfa2d9 --bench
running 1 test
test universe_ticks ... bench: 635,061 ns/iter (+/- 38,764)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.178 MB perf.data (2349 samples) ]
使用perf report加载分析结果,显示了所有的时间消耗在Universe::tick,如预期的那样:
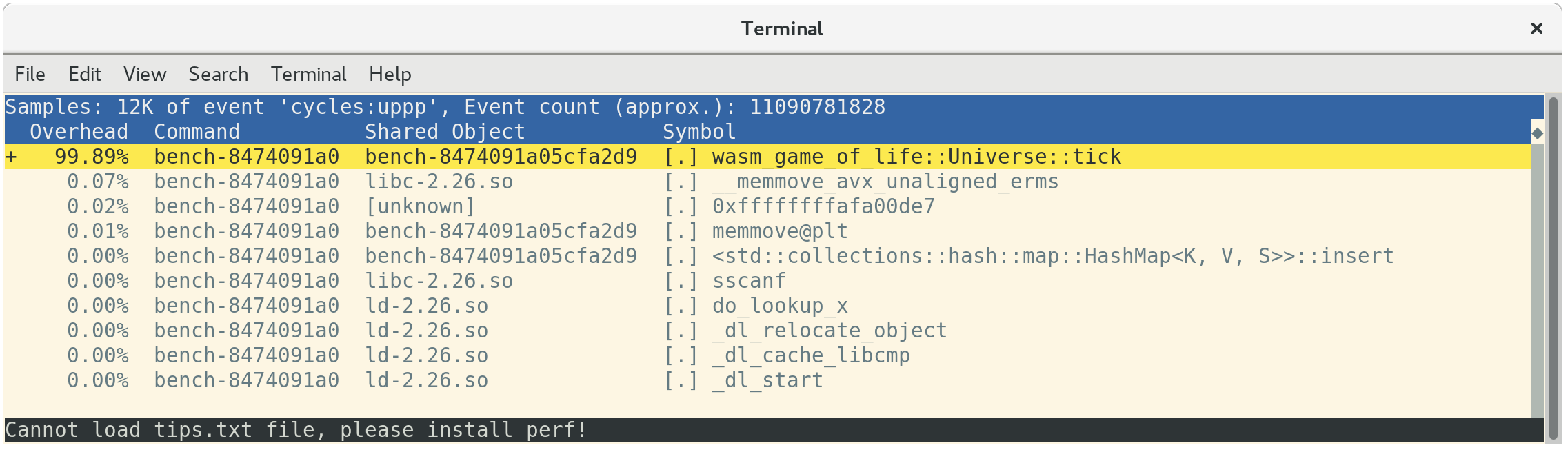
如果您按下a,perf将注释函数中哪个指令的执行时间。
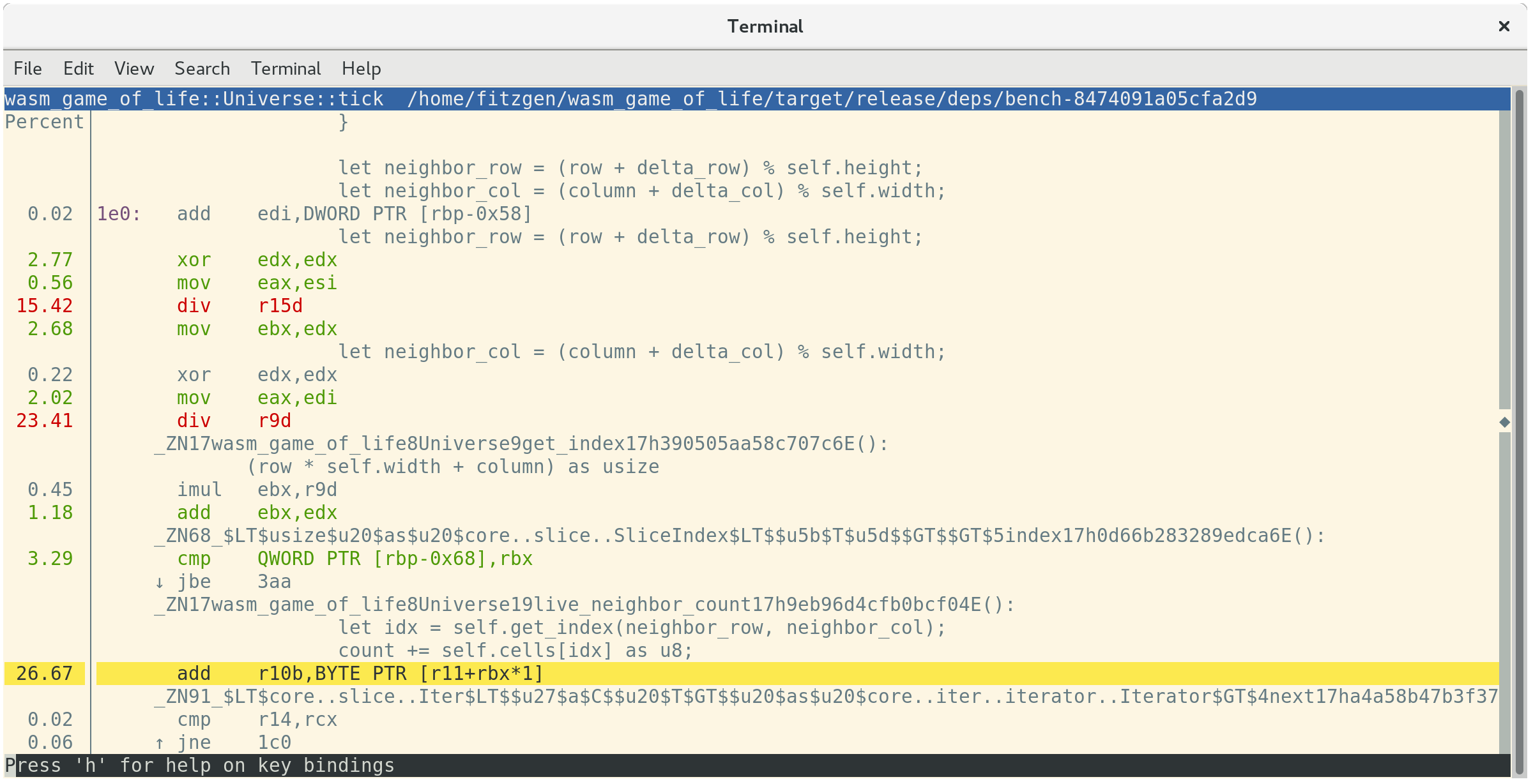
这告诉我们26.67%的时间花费在累加邻居单元格的值,23.41%的时间花费在获取邻居的列索引,
15.42%的时间花费在获取邻居的行索引。这三个是最昂贵的指令,第二和第三都是消耗在div指令。
这些div在Universe::live_neighbor_count中实现了模数索引逻辑。
回想一下wasm-game-of-life/src/lib.rs中的live_neighbor_count定义:
fn live_neighbor_count(&self, row: u32, column: u32) -> u8 {
let mut count = 0;
for delta_row in [self.height - 1, 0, 1].iter().cloned() {
for delta_col in [self.width - 1, 0, 1].iter().cloned() {
if delta_row == 0 && delta_col == 0 {
continue;
}
let neighbor_row = (row + delta_row) % self.height;
let neighbor_col = (column + delta_col) % self.width;
let idx = self.get_index(neighbor_row, neighbor_col);
count += self.cells[idx] as u8;
}
}
count
}
我们使用模数的原因是为了避免使用if时首(或末)行(或列)边缘情况的分支混淆代码。
但是即使对于最普通的场景我们也产生了div指令的花销,当行或列不再宇宙边缘的时候,
他们不需要模数包裹处理。相反的,如果我们对边缘情况使用if并展开循环,
分支应该会被CPU的分支预测器很好的预测到。
让我们这样重写live_neighbor_count:
fn live_neighbor_count(&self, row: u32, column: u32) -> u8 {
let mut count = 0;
let north = if row == 0 {
self.height - 1
} else {
row - 1
};
let south = if row == self.height - 1 {
0
} else {
row + 1
};
let west = if column == 0 {
self.width - 1
} else {
column - 1
};
let east = if column == self.width - 1 {
0
} else {
column + 1
};
let nw = self.get_index(north, west);
count += self.cells[nw] as u8;
let n = self.get_index(north, column);
count += self.cells[n] as u8;
let ne = self.get_index(north, east);
count += self.cells[ne] as u8;
let w = self.get_index(row, west);
count += self.cells[w] as u8;
let e = self.get_index(row, east);
count += self.cells[e] as u8;
let sw = self.get_index(south, west);
count += self.cells[sw] as u8;
let s = self.get_index(south, column);
count += self.cells[s] as u8;
let se = self.get_index(south, east);
count += self.cells[se] as u8;
count
}
现在让我们再次运行基准测试!这次输出到after.txt。
$ cargo bench | tee after.txt
Compiling wasm_game_of_life v0.1.0 (file:///home/fitzgen/wasm_game_of_life)
Finished release [optimized + debuginfo] target(s) in 0.82 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 87,258 ns/iter (+/- 14,632)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
看起来好多了!使用benchcmp工具和我们此前创建的两个文件,我们能看到现在有多好: tool and the two text files we created before:
$ cargo benchcmp before.txt after.txt
name before.txt ns/iter after.txt ns/iter diff ns/iter diff % speedup
universe_ticks 664,421 87,258 -577,163 -86.87% x 7.61
哇!提速了7.61倍!
WebAssembly有意映射到常见的硬件架构,但我们确实需要确保这个本机代码加速转换为WebAssembly也加快了速度。
让我们使用wasm-pack build重新构建.wasm然后刷新http://localhost:8080/。
在我的机器上,页面再次运行到60帧每秒了,并且浏览器的分析器记录另一个分析显示每个动画帧大约需要10毫秒。
成功!
练习
现在,下一个不用花太多精力就能产生效果的优化是移除
Universe::tick的分配和释放。 实现两个细胞缓冲区,Universe持有两个向量,在tick时不释放他们也不分配新的缓冲区。实现一个替代品,“实现”章节中的基于增量的设计,这时Rust代码返回一个包含状态改变的细胞的列表给JavaScript。 这会使得渲染到
<canvas>更快吗?你能实现这个设计而不需要在每次tick都分配一个增量的列表吗?正如我们的分析展示给我们的那样,2D的
<canvas>渲染不是特别快。 使用一个WebGL渲染器代替2D画布。 WebGL的版本有多快?在WebGL渲染遇到瓶颈前你能使宇宙变多大?